
#21. Finding the Sample Size Needed to Estimate a Population Proportion using StatCrunch
Please Subscribe here, thank you!!! https://goo.gl/JQ8Nys #21. Finding the Sample Size Needed to Estimate a Population Proportion using StatCrunch
From playlist Statistics Final Exam

This video explains how to determine mean, median and mode. It also provided examples. http://mathispower4u.yolasite.com/
From playlist Statistics: Describing Data

Is the Given Value a Statistic or Parameter? MyMathlab Homework
Please Subscribe here, thank you!!! https://goo.gl/JQ8Nys Is the Given Value a Statistic or Parameter? MyMathlab Homework
From playlist Statistics
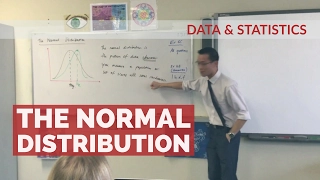
The Normal Distribution (1 of 3: Introductory definition)
More resources available at www.misterwootube.com
From playlist The Normal Distribution

Determine if the Given Value is from a Discrete or Continuous Data Set MyMathlab Statistics
Please Subscribe here, thank you!!! https://goo.gl/JQ8Nys Determine if the Given Value is from a Discrete or Continuous Data Set MyMathlab Statistics
From playlist Statistics

Statistics Lecture 3.3: Finding the Standard Deviation of a Data Set
https://www.patreon.com/ProfessorLeonard Statistics Lecture 3.3: Finding the Standard Deviation of a Data Set
From playlist Statistics (Full Length Videos)

Determine if the Value is a Statistic or Parameter MyMathlab Homework Problem
Please Subscribe here, thank you!!! https://goo.gl/JQ8Nys Determine if the Value is a Statistic or Parameter MyMathlab Homework Problem
From playlist Statistics

Statistics Lecture 6.3: The Standard Normal Distribution. Using z-score, Standard Score
https://www.patreon.com/ProfessorLeonard Statistics Lecture 6.3: Applications of the Standard Normal Distribution. Using z-score, Standard Score
From playlist Statistics (Full Length Videos)
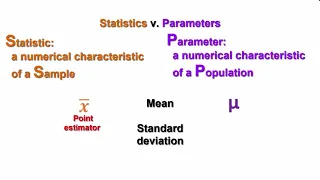
sample statistics versus population parameters
From playlist Unit 1: Descriptive Statistics

Introduction to Probability and Statistics 131B. Lecture 10.
UCI Math 131B: Introduction to Probability and Statistics (Summer 2013) Lec 10. Introduction to Probability and Statistics View the complete course: http://ocw.uci.edu/courses/math_131b_introduction_to_probability_and_statistics.html Instructor: Michael C. Cranston, Ph.D. License: Creativ
From playlist Introduction to Probability and Statistics 131B

Abstraction - Seminar 4 - Sufficient statistics and the Koopman-Pitman-Darmois theorem
This seminar series is on the relations among Natural Abstraction, Renormalisation and Resolution. This week Alexander Oldenziel explains some more of Wenworth's view of natural abstractions, presents the story of sufficient statistics and the Koopman-Pitman-Darmois theorem. The webpage f
From playlist Abstraction


Likelihood | Log likelihood | Sufficiency | Multiple parameters
See all my videos here: http://www.zstatistics.com/ *************************************************************** 0:00 Introduction 2:17 Example 1 (Discrete distribution: develop your intuition!) 7:25 Likelihood 8:52 Likelihood ratio 10:00 Likelihood function 11:05 Log likelihood funct
From playlist Statistical Inference (7 videos)
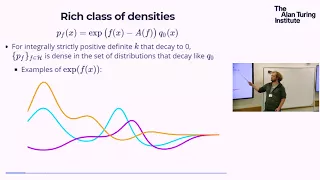
Score estimation with infinite-dimensional exponential families – Dougal Sutherland, UCL
Many problems in science and engineering involve an underlying unknown complex process that depends on a large number of parameters. The goal in many applications is to reconstruct, or learn, the unknown process given some direct or indirect observations. Mathematically, such a problem can
From playlist Approximating high dimensional functions

(ML 16.4) Why EM makes sense (part 1)
One can arrive at the EM algorithm in a natural way by trying to analytically maximize the likelihood, in an exponential family.
From playlist Machine Learning

Free response example: Significance test for a mean | AP Statistics | Khan Academy
AP Statistics free response on significance test for a mean. View more lessons or practice this subject at http://www.khanacademy.org/math/ap-statistics/tests-significance-ap/one-sample-t-test-mean/v/ap-statistics-free-response-on-significance-test-for-mean?utm_source=youtube&utm_medium=d
From playlist Significance tests (hypothesis testing) | AP Statistics | Khan Academy

Machine learning based statistical inference - Charnock - Workshop 2 - CEB T3 2018
Tom Charnock (IAP) / 25.10.2018 Machine learning based statistical inference ---------------------------------- Vous pouvez nous rejoindre sur les réseaux sociaux pour suivre nos actualités. Facebook : https://www.facebook.com/InstitutHenriPoincare/ Twitter : https://twitter.com/InHenr
From playlist 2018 - T3 - Analytics, Inference, and Computation in Cosmology

(ML 16.5) Why EM makes sense (part 2)
One can arrive at the EM algorithm in a natural way by trying to analytically maximize the likelihood, in an exponential family.
From playlist Machine Learning

Stefano Soatto: "Invariance and disentanglement in deep representations"
New Deep Learning Techniques 2018 "Invariance and disentanglement in deep representations" Stefano Soatto, University of California, Los Angeles (UCLA) Abstract: Theories of Deep Learning are like anatomical parts best not named explicitly in an abstract: Everyone seems to have one. That
From playlist New Deep Learning Techniques 2018

Find x given the z-score, sample mean, and sample standard deviation
Please Subscribe here, thank you!!! https://goo.gl/JQ8Nys Find x given the z-score, sample mean, and sample standard deviation
From playlist Statistics