
Softmax Function Explained In Depth with 3D Visuals
The softmax function is often used in machine learning to transform the outputs of the last layer of your neural network (the logits) into probabilities. In this video, I explain how the softmax function works and provide some intuition for thinking about it in higher dimensions. In additi
From playlist Machine Learning

The Softmax : Data Science Basics
All about the SOFTMAX function in machine learning!
From playlist Data Science Basics

Derivative of Sigmoid and Softmax Explained Visually
The derivative of the sigmoid function can be understood intuitively by looking at how the denominator of the function transforms the numerator. The derivative of the softmax function, which can be thought of as an extension of the sigmoid function to multiple classes, works in a very simi
From playlist Machine Learning

The Softmax neural network layer
A leave-nothing-out tour of the softmax function, including derivation, differentiation, and conceptual motivation. The original post is at https://e2eml.school/softmax.html It's part of a course where we build an image classifier out of a convolutional neural network. Come by for a visi
From playlist E2EML 322. Convolution in Two Dimensions

Activation Functions in Neural Networks (Sigmoid, ReLU, tanh, softmax)
#ActivationFunctions #ReLU #Sigmoid #Softmax #MachineLearning Activation Functions in Neural Networks are used to contain the output between fixed values and also add a non linearity to the output. Activation Functions play an important role in Machine Learning. In this video we discu
From playlist Deep Learning with Keras - Python

The SoftMax Derivative, Step-by-Step!!!
Here's step-by-step guide that shows you how to take the derivatives of the SoftMax function, as used as a final output layer in a Neural Networks. NOTE: This StatQuest assumes that you already understand the main ideas behind SoftMax. If not, check out the 'Quest: https://youtu.be/KpKog-
From playlist StatQuest

Transcendental Functions 19 The Function a to the power x.mp4
The function a to the power x.
From playlist Transcendental Functions

In this video, you’ll learn more about the difference between hard and soft skills. Visit https://www.gcflearnfree.org/subjects/work/ for our text-based Work & Career tutorials. This video includes information on: • Hard skills, which include physical skills that are important to your job
From playlist Critical Skills For Today
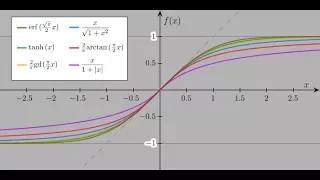
Sigmoid functions for population growth and A.I.
Some elaborations on sigmoid functions. https://en.wikipedia.org/wiki/Sigmoid_function https://www.learnopencv.com/understanding-activation-functions-in-deep-learning/ If you have any questions of want to contribute to code or videos, feel free to write me a message on youtube or get my co
From playlist Analysis

Kaggle Live Coding: Softmax from Scratch | Kaggle
Join Kaggle data scientist Rachael Tatman as she implements softmax from scratch. SUBSCRIBE : http://www.youtube.com/user/kaggledot... About Kaggle: Kaggle is the world's largest community of data scientists. Join us to compete, collaborate, learn, and do your data science work. Kaggle'
From playlist Kaggle Live Coding | Kaggle

Neural Networks Part 5: ArgMax and SoftMax
When your Neural Network has more than one output, then it is very common to train with SoftMax and, once trained, swap SoftMax out for ArgMax. This video give you all the details on these two methods so that you'll know when and why to use ArgMax or SoftMax. NOTE: This StatQuest assumes
From playlist StatQuest

PyTorch Tutorial 11 - Softmax and Cross Entropy
New Tutorial series about Deep Learning with PyTorch! ⭐ Check out Tabnine, the FREE AI-powered code completion tool I use to help me code faster: https://www.tabnine.com/?utm_source=youtube.com&utm_campaign=PythonEngineer * In this part we learn about the softmax function and the cross en
From playlist PyTorch Tutorials - Complete Beginner Course

7.9: TensorFlow.js Color Classifier: Softmax and Cross Entropy
In this video, I implement the last layer of the classifier model and cover the softmax activation function and cross entropy loss function. 🎥 Next Video: https://youtu.be/SyEZ5Yo2ec8 🔗 Crowdsource Color Data: https://github.com/CodingTrain/CrowdSourceColorData 🔗 TensorFlow.js: https://j
From playlist Session 7 - TensorFlow.js Color Classifier - Intelligence and Learning

Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (Paper Explained)
#ai #attention #transformer #deeplearning Transformers are famous for two things: Their superior performance and their insane requirements of compute and memory. This paper reformulates the attention mechanism in terms of kernel functions and obtains a linear formulation, which reduces th
From playlist Papers Explained

logit and softmax in deep learning
understanding what is logit and softmax in deep learning. all machine learning youtube videos from me, https://www.youtube.com/playlist?list=PLVNY1HnUlO26x597OgAN8TCgGTiE-38D6
From playlist Machine Learning

Lecture 4: Word Window Classification and Neural Networks
Lecture 4 introduces single and multilayer neural networks, and how they can be used for classification purposes. Key phrases: Neural networks. Forward computation. Backward propagation. Neuron Units. Max-margin Loss. Gradient checks. Xavier parameter initialization. Learning rates. Adagr
From playlist Lecture Collection | Natural Language Processing with Deep Learning (Winter 2017)

Linformer: Self-Attention with Linear Complexity (Paper Explained)
Transformers are notoriously resource-intensive because their self-attention mechanism requires a squared number of memory and computations in the length of the input sequence. The Linformer Model gets around that by using the fact that often, the actual information in the attention matrix
From playlist Papers Explained

In this video I show you how to use the tables function in Desmos.
From playlist Biomathematics