
In this video, I define a cool operation called the symmetrization, which turns any matrix into a symmetric matrix. Along the way, I also explain how to show that an (abstract) linear transformation is one-to-one and onto. Finally, I show how to decompose and matrix in a nice way, sort of
From playlist Linear Transformations
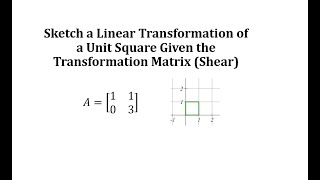
Sketch a Linear Transformation of a Unit Square Given the Transformation Matrix (Shear)
This video explains 2 ways to graph a linear transformation of a unit square on the coordinate plane.
From playlist Matrix (Linear) Transformations
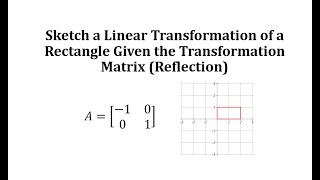
Sketch a Linear Transformation of a Rectangle Given the Transformation Matrix (Reflection)
This video explains 2 ways to graph a linear transformation of a rectangle on the coordinate plane.
From playlist Matrix (Linear) Transformations

Identify the Domain and Codomain of a Linear Transformation Given a Matrix
This video reviews how to determine the domain and codomain of a linear transformation given the standard matrix.
From playlist Matrix (Linear) Transformations

Find the Transformation Matrix Given Two Transformations in R2 Using an Inverse Matrix
This video explains how to use an inverse matrix to find a transformation matrix in R2 given two vector transformations.
From playlist Matrix (Linear) Transformations
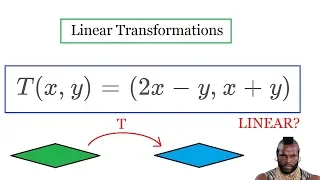
Showing something is a linear transformation Check out my Linear Equations playlist: https://www.youtube.com/playlist?list=PLJb1qAQIrmmD_u31hoZ1D335sSKMvVQ90 Subscribe to my channel: https://www.youtube.com/channel/UCoOjTxz-u5zU0W38zMkQIFw
From playlist Linear Transformations

Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 7 – Vanishing Gradients, Fancy RNNs
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/3c7n6jW Professor Christopher Manning & PhD Candidate Abigail See, Stanford University http://onlinehub.stanford.edu/ Professor Christopher Manning Thomas M. Sieb
From playlist Stanford CS224N: Natural Language Processing with Deep Learning Course | Winter 2019

A brief history of the Transformer architecture in NLP
🏛️ The Transformer architecture has revolutionized Natural Language Processing, being capable to beat the state-of-the-art on overwhelmingly numerous tasks! Check out this video for a brief history of the Transformer development. Related video: How do we check if a neural network has lear
From playlist The Transformer explained by Ms. Coffee Bean

[BERT] Pretranied Deep Bidirectional Transformers for Language Understanding (discussions) | TDLS
Toronto Deep Learning Series, 6 November 2018 Paper: https://arxiv.org/abs/1810.04805 Speaker: Danny Luo (Dessa) https://dluo.me/ Host: Ada Date: Nov 6th, 2018 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding We introduce a new language representation m
From playlist Natural Language Processing

Suppose you have two bases of the same space and the matrix of a linear transformation with respect to one bases. In this video, I show how to find the matrix of the same transformation with respect to the other basis, without ever having to figure out what the linear transformation does!
From playlist Linear Transformations

[BERT] Pretranied Deep Bidirectional Transformers for Language Understanding (algorithm) | TDLS
Toronto Deep Learning Series Host: Ada + @ML Explained - Aggregate Intellect - AI.SCIENCE Date: Nov 6th, 2018 Aggregate Intellect is a Global Marketplace where ML Developers Connect, Collaborate, and Build. -Connect with peers & experts at https://ai.science -Join our Slack Community:
From playlist Natural Language Processing

Determine if a Linear Transformation is One-to-One and/or Onto (R3 to R3)
This video explains how to determine if a given linear transformation is one-to-one and/or onto.
From playlist One-to-One and Onto Transformations

Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 13 – Contextual Word Embeddings
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/30j472S Professor Christopher Manning, Stanford University http://onlinehub.stanford.edu/ Professor Christopher Manning Thomas M. Siebel Professor in Machine Lear
From playlist Stanford CS224N: Natural Language Processing with Deep Learning Course | Winter 2019

World's Simplest Solid State Tesla Coil (SSTC): The Full Guide (w/ Plasma Channel + ThePlasmaPrince)
Enjoy this video? Be sure to check out my latest and greatest Tesla coil tutorial, which shows you how to build your own audio-modulated, class-E musical Tesla coil: https://www.youtube.com/watch?v=Hez-R-WF5P0 Wanting to build this circuit in a 220-240V region? Check out this video instea
From playlist Tesla Coils and High Voltage

Pierre-Alain Reynier : Transductions - Partie 2
Résumé : Après une introduction générale présentant les principaux modèles et problèmes étudiés, nous étudierons plus précisément trois sujets qui permettront d’illustrer des propriétés algorithmiques, des aspects algébriques et logiques de cette théorie : - caractérisation, décision et mi
From playlist Logic and Foundations

From playlist Transformations of the Number Line

BERT Transformers for Sentences: Python Code for Sentence Similarity, Edition 2022 | Part 3/3
A COLAB (3/3) Notebook to follow along with BERT model applied to calculate sentence similarity with encoder stack of transformers. Python code. TensorFlow and KERAS. Self attention. Frozen BERT models with operational added KERAS layers. Compare this to SBERT! Deep Bidirectional Encoder
From playlist SBERT: Python Code Sentence Transformers: a Bi-Encoder /Transformer model #sbert

BERT Transformers for Sentences: Python Code for Sentence Similarity, Update 2022 | Part 1/3
A COLAB (1/3) Notebook to follow along with BERT model applied to calculate sentence similarity with encoder stack of transformers. Python code. TensorFlow and KERAS. Self attention. Compare this to SBERT! Deep Bidirectional Encoder Representation Transformers for Language Understanding.
From playlist SBERT: Python Code Sentence Transformers: a Bi-Encoder /Transformer model #sbert

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805 Abstract: We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations
From playlist Best Of
