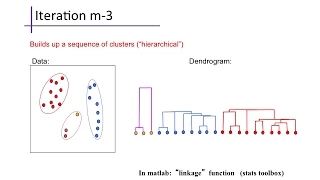
Clustering (2): Hierarchical Agglomerative Clustering
Hierarchical agglomerative clustering, or linkage clustering. Procedure, complexity analysis, and cluster dissimilarity measures including single linkage, complete linkage, and others.
From playlist cs273a


Introduction to Hierarchical Clustering with College Scorecard Data
Clustering is an unsupervised machine learning technique where data need not be labeled. The goal of clustering is to find like-items such as similar customers, similar products, or similar students, just to name a few. Popular clustering algorithms include K-means and hierarchical cluster
From playlist Fundamentals of Machine Learning

Hierarchical Clustering 4: the Lance-Williams algorithm
[http://bit.ly/s-link] The Lance-Williams algorithm provides a single, efficient algorithm to implement agglomerative clustering for different linkage types. We go over the algorithm and provide the update equations for single-link, complete-link and average-link definitions of inter-clust
From playlist Hierarchical Clustering

From playlist Clustering Algorithms

Introduction to Clustering Techniques | Mahout Clustering techniques | Mahout Clustering Tutorial
Watch Sample Class Recording: http://www.edureka.co/mahout?utm_source=youtube&utm_medium=referral&utm_campaign=clustering-tech Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some
From playlist Machine Learning with Mahout

We will look at the fundamental concept of clustering, different types of clustering methods and the weaknesses. Clustering is an unsupervised learning technique that consists of grouping data points and creating partitions based on similarity. The ultimate goal is to find groups of simila
From playlist Data Science in Minutes

Clustering (4): Gaussian Mixture Models and EM
Gaussian mixture models for clustering, including the Expectation Maximization (EM) algorithm for learning their parameters.
From playlist cs273a


MIT 6.034 Artificial Intelligence, Fall 2010 View the complete course: http://ocw.mit.edu/6-034F10 Instructor: Mark Seifter We begin by discussing neural net formulas, including the sigmoid and performance functions and their derivatives. We then work Problem 2 of Quiz 3, Fall 2008, whic
From playlist MIT 6.034 Artificial Intelligence, Fall 2010


Applied Machine Learning 2019 - Lecture 15 - Clustering and Mixture models
K-Means, DBSCAN, hierarchical clustering, Gaussian Mixture Models Slides and materials on the class website: https://www.cs.columbia.edu/~amueller/comsw4995s19/schedule/
From playlist Applied Machine Learning - Spring 2019

Clustering Algorithms | Data Science Algorithms | Edureka | ML Rewind - 3
🔥Machine Learning Training with Python: https://www.edureka.co/machine-learning-certification-training This Edureka video on "Clustering Algorithms" will help you understand the various aspects of clustering using K Means in Python. 🔴Subscribe to our channel to get video updates. Hit the
From playlist Machine Learning Tutorial in Python | Edureka

Applied ML 2020 - 14 - Clustering and Mixture Models
Course materials at https://www.cs.columbia.edu/~amueller/comsw4995s20/schedule/
From playlist Applied Machine Learning 2020

John Healy (5/3/21): Practical Clustering and Topological Data Analysis
I will give a topologically biased history of useful and popular clustering from a data science perspective with links to the language of topological data analysis. Another way to phrase that could be: useful topological data analysis from the perspective of a data science practitioner. Th
From playlist TDA: Tutte Institute & Western University - 2021

Machine Learning by Andrew Ng [Coursera] 0801 Unsupervised learning introduction 0802 K-means algorithm 0803 Optimization objective 0804 Random initialization 0805 Choosing the number of clusters
From playlist Machine Learning by Professor Andrew Ng

From playlist Big Data Analytics by Dr. Emmanuel Müller

Introduction to SNA. Lecture 5. Network communities.
Cohesive subgroups. Graph cliques. Network communities. Graph partitioning. Modularity. Edge Betweenness. Spectral partitioning. Modularity maximization. Heuristic methods. Label propagation. Fast community unfolding. Walktrap. Lecture slides: http://www.leonidzhukov.net/hse/2015/sna/lect
From playlist Introduction to SNA

Clustering is an unsupervised machine learning tool to reduce dimensionality and put similar data together. We can do clustering in hierarchical, or partitioning approaches, but we need a distance metric that follows some basic rules. In this video we discuss clustering, measuring distance
From playlist Materials Informatics
