Univariate (statistics)
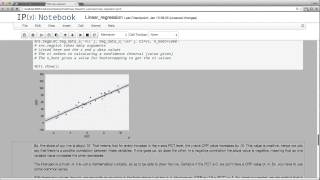
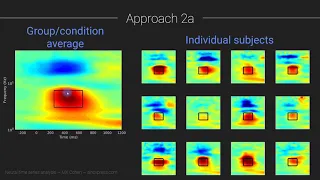
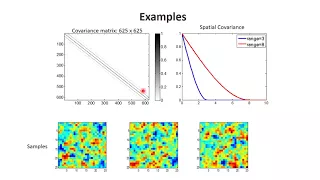
Univariate is a term commonly used in statistics to describe a type of data which consists of observations on only a single characteristic or attribute. A simple example of univariate data would be the salaries of workers in industry. Like all the other data, univariate data can be visualized using graphs, images or other analysis tools after the data is measured, collected, reported, and analyzed. (Wikipedia).