
Soft Skills Every Developer Should Master
Being a successful developer involves more than just writing high quality code. Watch this presentation to find out which soft skills every programmer should have. EVENT: WordCamp Europe, Paris, France, June 2017 SPEAKER: Andrew Nacin PERMISSIONS: The original content of this video is u
From playlist Soft Skills

(ML 11.4) Choosing a decision rule - Bayesian and frequentist
Choosing a decision rule, from Bayesian and frequentist perspectives. To make the problem well-defined from the frequentist perspective, some additional guiding principle is introduced such as unbiasedness, minimax, or invariance.
From playlist Machine Learning

Softmax Function Explained In Depth with 3D Visuals
The softmax function is often used in machine learning to transform the outputs of the last layer of your neural network (the logits) into probabilities. In this video, I explain how the softmax function works and provide some intuition for thinking about it in higher dimensions. In additi
From playlist Machine Learning

(ML 11.8) Bayesian decision theory
Choosing an optimal decision rule under a Bayesian model. An informal discussion of Bayes rules, generalized Bayes rules, and the complete class theorems.
From playlist Machine Learning

From playlist Decision Tree Learning

Decision trees are powerful and surprisingly straightforward. Here's how they are grown. Code: https://github.com/brohrer/brohrer.github.io/blob/master/code/decision_tree.py Slides: https://docs.google.com/presentation/d/1fyGhGxdGcwt_eg-xjlMKiVxstLhw42XfGz3wftSzRjc/edit?usp=sharing PERM
From playlist Data Science

In this video, you’ll learn more about the difference between hard and soft skills. Visit https://www.gcflearnfree.org/subjects/work/ for our text-based Work & Career tutorials. This video includes information on: • Hard skills, which include physical skills that are important to your job
From playlist Critical Skills For Today
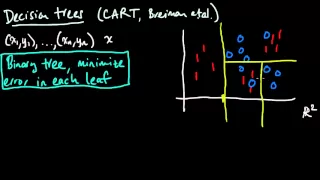
(ML 2.1) Classification trees (CART)
Basic intro to decision trees for classification using the CART approach. A playlist of these Machine Learning videos is available here: http://www.youtube.com/my_playlists?p=D0F06AA0D2E8FFBA
From playlist Machine Learning

Modern NLP: Second Surge of NLP - Attention-Session 3, part 1
RNN with Attention: architecture RNN with Attention: equations Intra-Attention Intra-Attention equations Attention types: hard vs soft, global vs local
From playlist Modern Natural Language Processing (hands on)

Lec 12 | MIT 6.451 Principles of Digital Communication II
Reed-Solomon Codes View the complete course: http://ocw.mit.edu/6-451S05 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.451 Principles of Digital Communication II
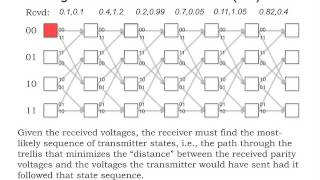
MIT 6.02 Introduction to EECS II: Digital Communication Systems, Fall 2012 View the complete course: http://ocw.mit.edu/6-02F12 Instructor: George Verghese This lecture starts with a review of encoding and decoding. The Viterbi algorithm, which includes a branch netric and a path metric,
From playlist MIT 6.02 Introduction to EECS II: Digital Communication Systems, Fall 2012

Stanford Seminar - A Superscalar Out-of-Order x86 Soft Processor for FPGA
Henry Wong University of Toronto, Intel June 5, 2019 Although FPGAs continue to grow in capacity, FPGA-based soft processors have grown little because of the difficulty of achieving higher performance in exchange for area. Superscalar out-of-order processor microarchitectures have been us
From playlist Stanford EE380-Colloquium on Computer Systems - Seminar Series

Lec 7 | MIT 6.451 Principles of Digital Communication II
Introduction to Finite Fields View the complete course: http://ocw.mit.edu/6-451S05 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.451 Principles of Digital Communication II

CMU Neural Nets for NLP 2017 (24): Advanced Search Algorithms
This lecture (by Daniel Clothiaux) for CMU CS 11-747, Neural Networks for NLP (Fall 2017) covers: * Beam Search * A*-type Search Slides: http://phontron.com/class/nn4nlp2017/assets/slides/nn4nlp-24-search.pdf Previous Video: https://youtu.be/oMB24_ao05A Next Video: https://youtu.be/XnwB
From playlist CMU Neural Nets for NLP 2017

Top 10 Soft Skills For Better Career In 2022 | 10 Soft Skills To Master In 2022 | Simplilearn
This video on Top 10 Soft Skills For Better Career In 2022 by Simplilearn, is focused on industry relevant soft skills that will elevate your profile according to the current IT standards. This softskill tutorial will cover the some most sought soft skills like communication, time manageme
From playlist Interview Tips and Career Advice | Soft Skills Training 🔥[2022 Updated]
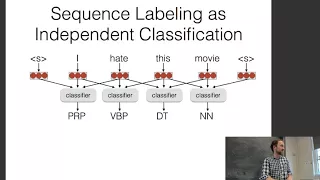
CMU Neural Nets for NLP 2017 (10): Structured Prediction
This lecture (by Graham Neubig) for CMU CS 11-747, Neural Networks for NLP (Fall 2017) covers: * Teacher Forcing and Exposure Bias * Local vs. Global, Label Bias * The Structured Perceptron * Structured Max-margin Objectives Slides: http://phontron.com/class/nn4nlp2017/assets/slides/nn4n
From playlist CMU Neural Nets for NLP 2017

CMU Neural Nets for NLP 2017 (9): Attention
This lecture (by Graham Neubig) for CMU CS 11-747, Neural Networks for NLP (Fall 2017) covers: * Attention * What do We Attend To? * Improvements to Attention * Specialized Attention Varieties * A Case Study: "Attention is All You Need" Slides: http://phontron.com/class/nn4nlp2017/assets
From playlist CMU Neural Nets for NLP 2017

Lec 15 | MIT 6.451 Principles of Digital Communication II
Trellis Representations of Binary Linear Block Codes View the complete course: http://ocw.mit.edu/6-451S05 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.451 Principles of Digital Communication II

Lec 19 | MIT 6.450 Principles of Digital Communications I, Fall 2006
Lecture 19: Baseband detection and complex Gaussian processes View the complete course at: http://ocw.mit.edu/6-450F06 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.450 Principles of Digital Communications, I Fall 2006

Focused vs Diffuse Thinking: Why Software Developers Need to Master Both Parts of Their Mind
In order to be highly effective and efficient, software developers need to learn to harness the power of the Focused and Diffuse states of mind! Watch this video to learn more about it.
From playlist Soft Skills