
Probability & Statistics (3 of 62) Definition of Sample Spaces & Factorials
Visit http://ilectureonline.com for more math and science lectures! In this video I will define what are sample spaces and factorials. Next video in series: http://youtu.be/EOk25Tb-1bM
From playlist Michel van Biezen: PROBABILITY & STATISTICS 1 BASICS

Powered by https://www.numerise.com/ Surveys & questionnaires (2)
From playlist Collecting data

Sampling (2 of 5: Introduction to Random Samples and Spreadsheets)
More resources available at www.misterwootube.com
From playlist Data Analysis
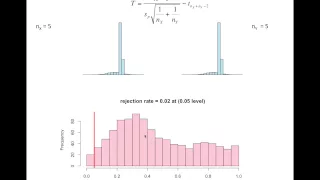

Hypothesis Test: Two Population Proportions
This video explains how to conduct a hypothesis test on two population proportions. http://mathispower4u.com
From playlist Hypothesis Test with Two Samples

How to calculate Samples Size Proportions
Introduction on how to calculate samples sizes from proportions. Describes the relationship of sample size and proportion. Like us on: http://www.facebook.com/PartyMoreStudyLess
From playlist Sample Size

Sampling Techniques & Cautions (Full Length)
I define and discuss the differences of observational studies and experiments. I then discuss the difference between a sample and a census. I introduce two types of sampling techniques that yield biased results...Voluntary Response and Convenience Sampling. I discuss Stratified Random S
From playlist AP Statistics

Introduction to Sampling & Populations (1 of 4: Graphing the sample means)
More resources available at www.misterwootube.com
From playlist Data Analysis

This lesson reviews sources of bias when conducting a survey or poll. Site: http://mathispower4u.com
From playlist Introduction to Statistics

Emulating Non-Linear Clustering - Jeremy Tinker
Jeremy Tinker - September 25, 2015 http://sns.ias.edu/~baldauf/Bias/index.html The interpretation of low-redshift galaxy surveys is more complicated than the interpretation of CMB temperature anisotropies. First, the matter distribution evolves nonlinearly at low redshift, limiting the u
From playlist Unbiased Cosmology from Biased Tracers

A Parallel Repetition Theorem for the GHZ Game - Justin Holmgren
Computer Science/Discrete Mathematics Seminar I Topic: A Parallel Repetition Theorem for the GHZ Game Speaker: Justin Holmgren Affiliation: Massachusetts Institute of Technology Date: October 19, 2020 For more video please visit http://video.ias.edu
From playlist Mathematics

Research Talk: Mutation Bias and Rates by Deepa Agashe
DISCUSSION MEETING SECOND PREPARATORY SCHOOL ON POPULATION GENETICS AND EVOLUTION ORGANIZERS Deepa Agashe (NCBS-TIFR, India) and Kavita Jain (JNCASR, India) DATE: 20 February 2023 to 24 February 2023 VENUE Madhava Lecture Hall, ICTS Bengaluru We plan an intensive 1-week preparatory school
From playlist SECOND PREPARATORY SCHOOL ON POPULATION GENETICS AND EVOLUTION

Lecture 9 - Approx/Estimation Error & ERM | Stanford CS229: Machine Learning (Autumn 2018)
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/3ptwgyN Anand Avati PhD Candidate and CS229 Head TA To follow along with the course schedule and syllabus, visit: http://cs229.stanford.edu/syllabus-autumn2018.h
From playlist Stanford CS229: Machine Learning Full Course taught by Andrew Ng | Autumn 2018

Asymptotic efficiency in high-dimensional covariance estimation – V. Koltchinskii – ICM2018
Probability and Statistics Invited Lecture 12.18 Asymptotic efficiency in high-dimensional covariance estimation Vladimir Koltchinskii Abstract: We discuss recent results on asymptotically efficient estimation of smooth functionals of covariance operator Σ of a mean zero Gaussian random
From playlist Probability and Statistics

Lecture 08 - Bias-Variance Tradeoff
Bias-Variance Tradeoff - Breaking down the learning performance into competing quantities. The learning curves. Lecture 8 of 18 of Caltech's Machine Learning Course - CS 156 by Professor Yaser Abu-Mostafa. View course materials in iTunes U Course App - https://itunes.apple.com/us/course/ma
From playlist Machine Learning Course - CS 156

Stanford CS229: Machine Learning | Summer 2019 | Lecture 13-Statistical Learning Uniform Convergence
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/3py8nGr Anand Avati Computer Science, PhD To follow along with the course schedule and syllabus, visit: http://cs229.stanford.edu/syllabus-summer2019.html
From playlist Stanford CS229: Machine Learning Course | Summer 2019 (Anand Avati)

Nexus Trimester - Krzysztof Onak (IBM T. J. Watson)
Communication Complexity of Learning Discrete Distributions Krzysztof Onak (IBM T. J. Watson) March 08, 2016 Abstract: The bounds on the sample complexity of most fundamental learning and testing problems for discrete distributions are well understood. We consider the scenario in which s
From playlist 2016-T1 - Nexus of Information and Computation Theory - CEB Trimester

Stanford CS229: Machine Learning | Summer 2019 | Lecture 12 - Bias and Variance & Regularization
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/3notMzh Anand Avati Computer Science, PhD To follow along with the course schedule and syllabus, visit: http://cs229.stanford.edu/syllabus-summer2019.html
From playlist Stanford CS229: Machine Learning Course | Summer 2019 (Anand Avati)

05 Spatial Data Analytics: Declustering
Walkthrough of a spatial data declustering (geostatistics) workflow in Python / Jupyter Notebook Slides with the GeostatsPy Python Package to correct for spatial sampling bias.
From playlist Spatial Data Analytics and Modeling

Sample bias: Response, Voluntary Response, Non-Response, Undercoverage, and Wording of Questions
From playlist Unit 4: Sampling and Experimental Design