
1.10 Mapping data using dictionaries in R statistical analysis and data science course Rstudio | V2
## Video # 2 In this chapter of the video series in the crash course in statistics and data science with R / Rstudio we will see the definition, utilization, and importance of using dictionaries for mapping in R. - Mapping in dataframes using dictionaries - Matching values with dictionar
From playlist R Tutorial | Rstudio

1.10 Mapping data with dictionary in R | statistical analysis and data science course Rstudio
## Video # 1: In this chapter of the video series in the crash course in statistics and data science with R / Rstudio we will see the definition, utilization, and importance of using dictionaries for mapping in R. We discuss among others ideas: - What is a dictionary - Dictionary usin
From playlist R Tutorial | Rstudio

In this tutorial I show a few more notations and share a few more thoughts on mappings.
From playlist Abstract algebra

10b Data Analytics: Spatial Continuity
Lecture on the impact of spatial continuity to motivate characterization and modeling of spatial continuity.
From playlist Data Analytics and Geostatistics

SCATTERPLOTS: Visualize Relationships Between Two Scale Variables (4-4)
Scatter Diagram (a.k.a. Scatterplot) is a graph used with correlation and regression. It summarizes the relationship between two quantitative variables. Trendline (a.k.a. Regression line) approximates the relationship between the two variables. A pair of scale variables, X and Y, are plott
From playlist Data Visualization for Variables in Statistics (WK 4 - QBA 237)

10c Data Analytics: Variogram Introduction
Lecture on the variogram as a measure to quantify spatial continuity.
From playlist Data Analytics and Geostatistics

1.5 Mapping and dictionaries in Python | Encoding | Data science and analysis course | Tutorial
In this episode in the crash course tutorial of statistics and data science with Python we'll discuss the creation and manipulation of dictionaries in Python for mapping and encoding/matching data frames variables. Additionally, we discuss among others: - Why to use dictionaries?: mappin
From playlist Python

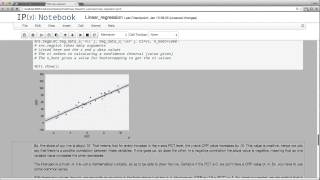
Linear regression is used to compare sets or pairs of numerical data points. We use it to find a correlation between variables.
From playlist Learning medical statistics with python and Jupyter notebooks

Seminar 5: Tom Mitchell - Neural Representations of Language
MIT RES.9-003 Brains, Minds and Machines Summer Course, Summer 2015 View the complete course: https://ocw.mit.edu/RES-9-003SU15 Instructor: Tom Mitchell Modeling the neural representations of language using machine learning to classify words from fMRI data, predictive models for word feat
From playlist MIT RES.9-003 Brains, Minds and Machines Summer Course, Summer 2015


At OSCON 2008, Toby Segaran, author of Programming Collective Intelligence (O'Reilly), shares his thoughts on technology, open source, and how collective intelligence is put to use in Freebase.
From playlist OSCON 2008

An introduction to Natural Language Processing enabled applications and Question by Asha Subramanian
SUMMER SCHOOL FOR WOMEN IN MATHEMATICS AND STATISTICS POPULAR TALKS (TITLE AND ABSTRACT) June 13, Monday, 15:45 - 16:45 hrs Asha Subramanian (Semantic Web India Private Limited) Title: An introduction to Natural Language Processing enabled applications and Question Answer Systems Abs
From playlist Summer School for Women in Mathematics and Statistics - 2022

Jean-Claude Belfiore - Beyond the statistical perspective on deep learning,...
Talk at the school and conference “Toposes online” (24-30 June 2021): https://aroundtoposes.com/toposesonline/ Beyond the statistical perspective on deep learning, the toposic point of view: Invariance and semantic information (joint work with Daniel Bennequin) The last decade has witnes
From playlist Toposes online

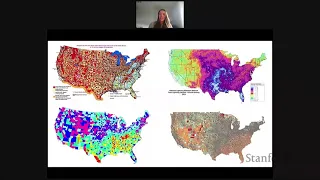
Stanford Seminar - Driving Exploratory Visualization through Perception & Cognition
Danielle Szafir University of North Carolina - Chapel Hill November 5, 2021 Visualizations allow analysts to rapidly explore and make sense of their data. The ways we visualize data directly influence the conclusions we draw and decisions we make; however, our knowledge of how visualizati
From playlist Stanford Seminars

Statistics Lecture 3.3: Finding the Standard Deviation of a Data Set
https://www.patreon.com/ProfessorLeonard Statistics Lecture 3.3: Finding the Standard Deviation of a Data Set
From playlist Statistics (Full Length Videos)


Summary Statistics | Introduction to Data Mining part 21
In this Data Mining Fundamentals tutorial, we continue our discussion on data exploration and visualization. We discuss summary statistics and the frequency and mode of an attribute. Summary statistics are numbers that summarize properties of data, and the frequency of an attribute value i
From playlist Introduction to Data Mining
