
Introduction to this lecture series on perioperative management.
From playlist Perioperative Patient Care _ Demo
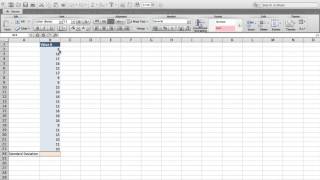
The dispersion of data by means of the standard deviation.
From playlist Medical Statistics

From playlist Trigonometry TikToks

(PP 6.1) Multivariate Gaussian - definition
Introduction to the multivariate Gaussian (or multivariate Normal) distribution.
From playlist Probability Theory
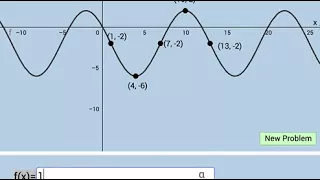
Modeling with Trigonometric Functions! (Formative Assessment w/Feedback)
Link: https://www.geogebra.org/m/cuCwguXP BGM: Simeon Smith
From playlist Trigonometry: Dynamic Interactives!

VQ-GAN | PyTorch Implementation
In this video we are implementing the famous Vector Quantized Generative Adversarial Networks (VQGAN) paper using PyTorch. VQGAN is a generative model for image modeling. It was introduced in Taming Transformers for High-Resolution Image Synthesis. The concept is build upon two stages. The
From playlist Paper Implementations

Vector Quantized Generative Adversarial Networks (VQGAN) is a generative model for image modeling. It was introduced in Taming Transformers for High-Resolution Image Synthesis. The concept is build upon two stages. The first stage learns in an autoencoder-like fashion by encoding images in
From playlist Paper Explanations

Irrigation Efficiencies - Part 1
From playlist TEMP 1

Lecture 03 Perioperative management of the diabetic patient part 1
We move on to the perioperative care of the diabetic patient (part 1).
From playlist Perioperative Patient Care _ Demo

From playlist Trigonometry TikToks

Statistics 5_1 Confidence Intervals
In this lecture explain the meaning of a confidence interval and look at the equation to calculate it.
From playlist Medical Statistics

VQGAN: Taming Transformers for High-Resolution Image Synthesis [Paper Explained]
The authors introduce VQGAN which combines the efficiency of convolutional approaches with the expressivity of transformers. VQGAN is essentially a GAN that learns a codebook of context-rich visual parts and uses it to quantize the bottleneck representation at every forward pass. The self-
From playlist Computer Vision

Marc Levoy - Lectures on Digital Photography - Lecture 13 (04May16).mp4
This is one of 18 videos representing lectures on digital photography, from a version of my Stanford course CS 178 that was recorded at Google in Spring 2016. A web site that includes all 18 videos, my slides, and the course schedule, applets, and assignments is http://sites.google.com/sit
From playlist Stanford: Digital Photography with Marc Levoy | CosmoLearning Computer Science

Stable Diffusion: High-Resolution Image Synthesis with Latent Diffusion Models | ML Coding Series
❤️ Become The AI Epiphany Patreon ❤️ https://www.patreon.com/theaiepiphany 👨👩👧👦 Join our Discord community 👨👩👧👦 https://discord.gg/peBrCpheKE If you want to understand how stable diffusion exactly works behind the scenes this video is for you. I do a deep dive into the code behind
From playlist Computer Vision

Speech and Audio Processing 4: Speech Coding I - Professor E. Ambikairajah
Speech and Audio Processing Speech Coding - Lecture notes available from: http://eemedia.ee.unsw.edu.au/contents/elec9344/LectureNotes/
From playlist ELEC9344 Speech and Audio Processing by Prof. Ambikairajah

Joan Bruna & Michael Bronstein Interview - Geometric Deep Learning
This week on the podcast we’re featuring a series of conversations from the NIPs conference in Long Beach, California. I attended a bunch of talks and learned a ton, organized an impromptu roundtable on Building AI Products, and met a bunch of great people, including some former TWiML Talk
From playlist Interviews

MIT MIT 6.003 Signals and Systems, Fall 2011 View the complete course: http://ocw.mit.edu/6-003F11 Instructor: Dennis Freeman License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.003 Signals and Systems, Fall 2011

2 Amazing Ideas in Latent Diffusion Models LDM w/ VAE, U-Net & CLIP: Generative AI #stablediffusion
New Latent Diffusion Models, LDM by Rombach & Blattmann, 2022, run the diffusion process in latent space instead of pixel space, making training cost lower and inference speed faster. Insights from a theoretical physicist applying Markov chains, UNet data augmentation theory. Keywords: sta
From playlist Stable Diffusion / Latent Diffusion models for Text-to-Image AI

Trigonometry 8 The Tangent and Cotangent of the Sum and Difference of Two Angles.mov
Derive the tangent and cotangent trigonometric identities.
From playlist Trigonometry

Twitch Talks - Image Computation
Presenter: Shadi Ashnai Wolfram Research developers demonstrate the new features of Version 12 of the Wolfram Language that they were responsible for creating. Previously broadcast live on May 14, 2019 at twitch.tv/wolfram. For more information, visit: https://www.wolfram.com/language/12/
From playlist Twitch Talks