


Linear regression (5): Bias and variance
Inductive bias; variance; relationship to over- & under-fitting
From playlist cs273a


From playlist Statistical Regression

Overfitting 1: over-fitting and under-fitting
[http://bit.ly/overfit] When building a learning algorithm, we want it to work well on the future data, not on the training data. Many algorithms will make perfect predictions on the training data, but perform poorly on the future data. This is known as overfitting. In this video we provid
From playlist Overfitting

Is the Curse of Dimensionality the same as overfitting?
#machinelearning #shorts #datascience
From playlist Quick Machine Learning Concepts

Machine Learning with Imbalanced Data - Part 3 (Over-sampling, SMOTE, and Imbalanced-learn)
In this video, we discuss the class imbalance problem and how to use over-sampling methods to address this problem. We use the thyroid data set and the logistic regression classifier to train binary classifiers on the original data set and the preprocessed data. We discuss uniform sampling
From playlist Machine Learning with Imbalanced Data - Dr. Data Science Series

Machine Learning with Imbalanced Data - Part 5 (Ensemble learning, Bagging classifier)
In this video, we discuss the use of ensemble learning strategies to address the class imbalance problem. Therefore, one can use a combination of data-level preprocessing methods and cost-sensitive learning to improve the performance of classifiers on class-imbalanced data sets. #Imbalan
From playlist Machine Learning with Imbalanced Data - Dr. Data Science Series
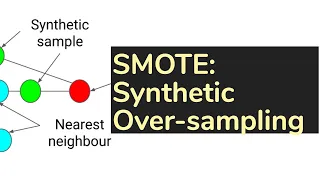
TDLS - Classics: SMOTE, Synthetic Minority Over-sampling Technique (algorithm)
Toronto Deep Learning Series, 26 November 2018 Paper: https://arxiv.org/pdf/1106.1813.pdf Speaker: Jason Grunhut (Telus Digital) Host: Telus Digital Date: Nov 26th, 2018 SMOTE: Synthetic Minority Over-sampling Technique An approach to the construction of classifiers from imbalanced da
From playlist Math and Foundations

Machine Learning with Imbalanced Data -Part 4 (Undersampling, Clustering-Based Prototype Generation)
In this video, we discuss under-sampling techniques for learning from imbalanced data sets, including random sampling and clustering-based prototype generation. We also see how to implement these techniques using NumPy, Scikit-learn, and Imbalanced-learn in Python. We notice that the proto
From playlist Machine Learning with Imbalanced Data - Dr. Data Science Series

Applied Machine Learning 2019 - Lecture 11 - Imbalanced data
Undersampling, oversampling, SMOTE, Easy Ensembles Class website with slides and more materials: https://www.cs.columbia.edu/~amueller/comsw4995s19/schedule/
From playlist Applied Machine Learning - Spring 2019

Introduction (4): Complexity and Overfitting
Simple vs complex models; training vs testing error; overfitting
From playlist cs273a

This is why you should care about unbalanced data .. as a data scientist
What do you do when your data has lots more negative examples than positive ones? Link to Code : https://github.com/ritvikmath/YouTubeVideoCode/blob/main/Unbalanced%20Data.ipynb My Patreon : https://www.patreon.com/user?u=49277905
From playlist Data Science Concepts

Daniel Rueckert: "Deep learning in medical imaging"
New Deep Learning Techniques 2018 "Deep learning in medical imaging: Techniques for image reconstruction, super-resolution and segmentation" Daniel Rueckert, Imperial College London Abstract: This talk will introduce framework for reconstructing MR images from undersampled data using a d
From playlist New Deep Learning Techniques 2018

Machine Learning for Everybody – Full Course
Learn Machine Learning in a way that is accessible to absolute beginners. You will learn the basics of Machine Learning and how to use TensorFlow to implement many different concepts. ✏️ Kylie Ying developed this course. Check out her channel: https://www.youtube.com/c/YCubed ⭐️ Code and
From playlist Data Science


Data leakage during data preparation? | Using AntiPatterns to avoid MLOps Mistakes
How can data leakage happen during data preparation? Find out here, where Ms. Coffee Bean is visualizing the answer to this question -- as it was answered by the paper “Using AntiPatterns to avoid MLOps Mistakes”. Paper explained 📄: Muralidhar, Nikhil, Sathappah Muthiah, Patrick Butler, M
From playlist Explained AI/ML in your Coffee Break

Overfitting 2: training vs. future error
[http://bit.ly/overfit] Training error is something we can always compute for a (supervised) learning algorithm. But what we want is the error on the future (unseen) data. We define the generalization error as the expected error of all possible data that could come in the future. We cannot
From playlist Overfitting

Randomized SVD: Power Iterations and Oversampling
This video discusses the randomized SVD and how to make it more accurate with power iterations (multiple passes through the data matrix) and oversampling. Book Website: http://databookuw.com Book PDF: http://databookuw.com/databook.pdf These lectures follow Chapter 1 from: "Data-Drive
From playlist Data-Driven Science and Engineering