
Probability & Statistics (52 of 62) Permutations and Combinations - Example 17
Visit http://ilectureonline.com for more math and science lectures! In this video I will find the number of nut mixtures can be made with 4 different nuts. Next video in series: http://youtu.be/PH7UhwQXllY
From playlist Michel van Biezen: PROBABILITY & STATISTICS 1 BASICS

Types of Colloids and Their Properties
Earlier we learned that as far as mixtures go, we can have homogeneous solutions, or totally heterogeneous mixtures, where components don't mix. But there are actually intermediary mixtures, where substances mix to some limited degree. Let's learn about colloids as well as suspensions! Wa
From playlist General Chemistry

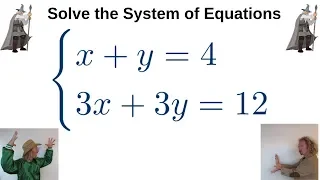
Systems of Equations Two Variables Two Equations Infinitely Many Solutions
Please Subscribe here, thank you!!! https://goo.gl/JQ8Nys Systems of Equations Two Variables Two Equations Infinitely Many Solutions
From playlist Systems of Equations
From playlist the absolute best of stereolab

Review Questions (Simultaneous Equations)
More resources available at www.misterwootube.com
From playlist Types of Relationships

The alternating series. Test for convergence.
From playlist Advanced Calculus / Multivariable Calculus

Interval of Convergence (silent)
Finding the interval of convergence for power series
From playlist 242 spring 2012 exam 3

What is a solution? | Solutions | Chemistry | Don't Memorise
What is a solution? You would say it is a mixture of two or more liquids. But is it so? Are solutions just mixtures of liquids? Watch this video to know the answers to these questions. In this video, we will learn: 0:00 What is a mixture? 0:49 properties of mixtures 2:08 Types of mixtur
From playlist Chemistry

Lecture 10B : Mixtures of Experts
Neural Networks for Machine Learning by Geoffrey Hinton [Coursera 2013] Lecture 10B : Mixtures of Experts
From playlist Neural Networks for Machine Learning by Professor Geoffrey Hinton [Complete]


Lecture 10.2 — Mixtures of Experts [Neural Networks for Machine Learning]
Lecture from the course Neural Networks for Machine Learning, as taught by Geoffrey Hinton (University of Toronto) on Coursera in 2012. Link to the course (login required): https://class.coursera.org/neuralnets-2012-001
From playlist [Coursera] Neural Networks for Machine Learning — Geoffrey Hinton

One Neural network learns EVERYTHING ?!
We explore a neural network architecture that can solve multiple tasks: multimodal Neural Network. We discuss important components and concepts along the way. If you like this video, hit that like button. If you really like this video, hit that SUBSCRIBE button. And if you just love me hi
From playlist Deep Learning Research Papers

Sparse Expert Models: Past and Future
Install NLP Libraries https://www.johnsnowlabs.com/install/ Register for Healthcare NLP Summit 2023: https://www.nlpsummit.org/#register Watch all NLP Summit 2022 sessions: https://www.nlpsummit.org/nlp-summit-2022-watch-now/ Presented by: -Barret, Zoph, Member of the Technical Staff
From playlist NLP Summit 2022

Lecture 10/16 : Combining multiple neural networks to improve generalization
Neural Networks for Machine Learning by Geoffrey Hinton [Coursera 2013] 10A Why it helps to combine models 10B Mixtures of Experts 10C The idea of full Bayesian learning 10D Making full Bayesian learning practical 10E Dropout: an efficient way to combine neural nets
From playlist Neural Networks for Machine Learning by Professor Geoffrey Hinton [Complete]
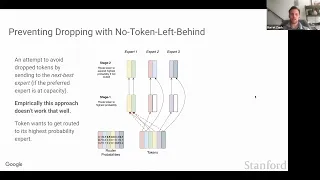
CS25 I Stanford Seminar - Mixture of Experts (MoE) paradigm and the Switch Transformer
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computat
From playlist Stanford Seminars

Sylvia Frühwirth-Schnatter: Bayesian econometrics in the Big Data Era
Abstract: Data mining methods based on finite mixture models are quite common in many areas of applied science, such as marketing, to segment data and to identify subgroups with specific features. Recent work shows that these methods are also useful in micro econometrics to analyze the beh
From playlist Probability and Statistics


GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Paper Explained)
Google builds a 600 billion parameter transformer to do massively multilingual, massive machine translation. Interestingly, the larger model scale does not come from increasing depth of the transformer, but from increasing width in the feedforward layers, combined with a hard routing to pa
From playlist Papers Explained

Mixture Models 5: how many Gaussians?
Full lecture: http://bit.ly/EM-alg How many components should we use in our mixture model? We can cross-validate to optimise the likelihood (or some other objective function). We can also use Occam's razor, formalised as the Bayes Information Criterion (BIC) or Akaike Information Criterio
From playlist Mixture Models