
Scheduling: The List Processing Algorithm Part 1
This lesson explains and provides an example of the list processing algorithm to make a schedule given a priority list. Site: http://mathispower4u.com
From playlist Scheduling

This lesson introduces the topic of scheduling and define basic scheduling vocabulary. Site: http://mathispower4u.com
From playlist Scheduling
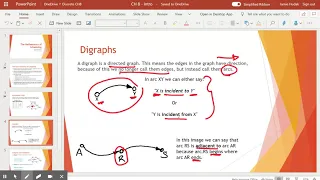
Into to the Mathematics of Scheduling
Terminology explained includes preference schedule, digraphs, tasks, arcs, processors, and timelines.
From playlist Discrete Math

Scheduling: The List Processing Algorithm Part 2
This lesson explains and provides an example of the list processing algorithm to create a digraph and make a schedule. Site: http://mathispower4u.com
From playlist Scheduling

Scheduling: The Decreasing Time Algorithm
This lesson explains how to use the decreasing time algorithm to create a priority list and then a schedule. Site: http://mathispower4u.com
From playlist Scheduling
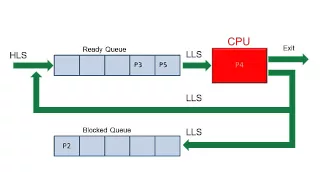
An animation showing the main features of a process scheduling system including the ready queue, blocked queue, high level scheduler and low level scheduler. It explains the principle of a round robin scheduling algorithm.
From playlist Operating Systems

Scheduling: The Critical Path Algorithm Version 1 (Part 1)
This lesson explains how to create a priority list using version 1 of the critical path algorithm. Site: http://mathispower4u.com
From playlist Scheduling

Time Management Tutorial - Tips on scheduling meetings
Learn tips and best practices for scheduling a meeting. Explore more Time Management courses and advance your skills on LinkedIn Learning: https://www.linkedin.com/learning/topics/time-management-3?trk=sme-youtube_M140599-20-03_learning&src=yt-other This is an excerpt from "Time Managemen
From playlist Time Management

What is Job Scheduling | Error Hamdling Concept | Data Warehousing Tutorial | Edureka
***** Data Warehousing & BI Training: https://www.edureka.co/data-warehousing-and-bi ***** The allocation of system resources to various tasks, known as job scheduling, is a major assignment of the operating system. The system maintains prioritized queues of jobs waiting for CPU time and
From playlist Data Warehousing Tutorial Videos

Lec 14 | MIT 6.035 Computer Language Engineering, Fall 2005
Instruction Scheduling View the complete course: http://ocw.mit.edu/6-035F05 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.035 Computer Language Engineering, Fall 2005

Lec 15 | MIT 6.035 Computer Language Engineering, Fall 2005
Register Allocation View the complete course: http://ocw.mit.edu/6-035F05 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.035 Computer Language Engineering, Fall 2005

Stanford Seminar - A Superscalar Out-of-Order x86 Soft Processor for FPGA
Henry Wong University of Toronto, Intel June 5, 2019 Although FPGAs continue to grow in capacity, FPGA-based soft processors have grown little because of the difficulty of achieving higher performance in exchange for area. Superscalar out-of-order processor microarchitectures have been us
From playlist Stanford EE380-Colloquium on Computer Systems - Seminar Series

Lec 7 | MIT 6.033 Computer System Engineering, Spring 2005
Virtual Processors: Threads and Coordination View the complete course at: http://ocw.mit.edu/6-033S05 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.033 Computer System Engineering, Spring 2005

Rec 5 | MIT 6.189 Multicore Programming Primer, IAP 2007
Recitation 5: Cell profiling tools License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.189 Multicore Programming Primer, January (IAP) 2007

Recitation 4: Cell debugging tools | MIT 6.189 Multicore Programming Primer, IAP 2007
* NOTE: Recitations 1-3 are not available. MIT 6.189 Multicore Programming Primer, IAP 2007 View the complete course: http://ocw.mit.edu/6-189IAP07 Instructors: Rodric Rabbah, Saman Amarasinghe License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at
From playlist MIT 6.189 Multicore Programming Primer, January (IAP) 2007

Kernel Recipes 2018 - CPU Idle Loop Rework - Rafael J. Wysocki
The CPU idle loop is the piece of code executed by logical CPUs if they have no tasks to run. If the CPU supports idle states allowing it to draw less power while not executing any instructions, the idle loop invokes a CPU idle governor to select the most suitable idle state for the CPU an
From playlist Kernel Recipes 2018

MIT 6.172 Performance Engineering of Software Systems, Fall 2018 Instructor: Julian Shun View the complete course: https://ocw.mit.edu/6-172F18 YouTube Playlist: https://www.youtube.com/playlist?list=PLUl4u3cNGP63VIBQVWguXxZZi0566y7Wf Professor Shun discusses races and parallelism, how ci
From playlist MIT 6.172 Performance Engineering of Software Systems, Fall 2018

Stanford Seminar - KUtrace 2020
Dick Sites February 5, 2020 Observation tools for understanding occasionally-slow performance in large-scale distributed transaction systems are not keeping up with the complexity of the environment. The same applies to large database systems, to real-time control systems in cars and airp
From playlist Stanford EE380-Colloquium on Computer Systems - Seminar Series

The intuitive idea of a function
Learning Objectives: Express the idea of a function as an "instruction", a "graph" and a "machine" that take inputs and spit out outputs. However there are constraints: every input must have a corresponding output, and more specifically just ONE corresponding output. ********************
From playlist Discrete Math (Full Course: Sets, Logic, Proofs, Probability, Graph Theory, etc)

Speaker: Michael Steil How VMware, VirtualPC and Parallels actually work Virtualization is rocket science. In cooperation with the host operating system, VMware takes over complete control of the machine hundreds of times a second, handles pagetables completely manually, and may chose t
From playlist 23C3: Who can you trust