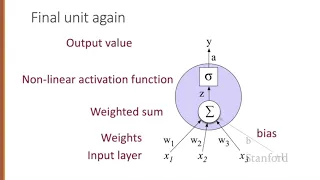
Neural Networks 1 Neural Units
From playlist Week 5: Neural Networks

Backpropagation explained | Part 3 - Mathematical observations
We have focused on the mathematical notation and definitions that we would be using going forward to show how backpropagation mathematically works to calculate the gradient of the loss function. We'll start making use of what we learned and applying it in this video, so it's crucial that y
From playlist Deep Learning Fundamentals - Intro to Neural Networks


Neural Networks and Deep Learning
This lecture explores the recent explosion of interest in neural networks and deep learning in the context of 1) vast and increasing data sets, and 2) rapidly improving computational hardware, which have enabled the training of deep neural networks. Book website: http://databookuw.com/
From playlist Intro to Data Science

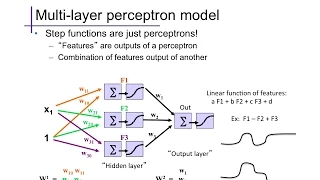
The basic form of a feed-forward multi-layer perceptron / neural network; example activation functions.
From playlist cs273a

Deep Learning Lecture 3.1 - Greetings
Welcome to the Deep Learning Lecture on Multilayer Perceptrons
From playlist Deep Learning Lecture

11A. Networks 3: The Future of Computational Biology: Cellular, Developmental, Social, E...
MIT HST.508 Genomics and Computational Biology, Fall 2002 Instructor: George Church View the complete course: https://ocw.mit.edu/courses/hst-508-genomics-and-computational-biology-fall-2002/ YouTube Playlist: https://www.youtube.com/playlist?list=PLUl4u3cNGP61gaHWysmlYNeGsuUI8y5GV We'll
From playlist HST.508 Genomics and Computational Biology, Fall 2002

Neural Network Training (Part 4): Backpropagation
In the previous video we saw how to calculate the gradients from training. In this video, we will see how to actually update the weights, using the gradients. Backpropagation is a very simple training algorithm. Other more complex algorithms can be used to update the weights as well.
From playlist Neural Networks by Jeff Heaton

Function Entropy in Deep-Learning Networks – Mean Field Behaviour and Large... by David Saad
DISCUSSION MEETING : STATISTICAL PHYSICS OF MACHINE LEARNING ORGANIZERS : Chandan Dasgupta, Abhishek Dhar and Satya Majumdar DATE : 06 January 2020 to 10 January 2020 VENUE : Madhava Lecture Hall, ICTS Bangalore Machine learning techniques, especially “deep learning” using multilayer n
From playlist Statistical Physics of Machine Learning 2020

Masayuki Ohzeki: "Quantum annealing and machine learning - new directions of quantum"
Machine Learning for Physics and the Physics of Learning 2019 Workshop IV: Using Physical Insights for Machine Learning "Quantum annealing and machine learning - new directions of quantum" Masayuki Ohzeki - Tohoku University Abstract: Quantum annealing is a generic solver of combinator
From playlist Machine Learning for Physics and the Physics of Learning 2019

Seventh SIAM Activity Group on FME Virtual Talk
Speaker: Ruimeng Hu, Assistant Professor in the Department of Mathematics and the Department of Statistics and Applied Probability, University of California Santa Barbara Title: Deep fictitious play for stochastic differential games Speaker: Max Reppen, Assistant Professor, Questrom Scho
From playlist SIAM Activity Group on FME Virtual Talk Series

Tales of Axion DM Substructure by Javier Redondo
PROGRAM LESS TRAVELLED PATH OF DARK MATTER: AXIONS AND PRIMORDIAL BLACK HOLES (ONLINE) ORGANIZERS: Subinoy Das (IIA, Bangalore), Koushik Dutta (IISER, Kolkata / SINP, Kolkata), Raghavan Rangarajan (Ahmedabad University) and Vikram Rentala (IIT Bombay) DATE: 09 November 2020 to 13 Novemb
From playlist Less Travelled Path of Dark Matter: Axions and Primordial Black Holes (Online)

John Mercer (1) - Intracellular transport by (and other functions of) Myosins.
I created this video with the YouTube Video Editor (http://www.youtube.com/editor) PROGRAM:Axonal Transport and Neurodgenerative Disorders DATES:Sunday 13 Jan, 2013 - Saturday 26 Jan, 2013 VENUE:IIT Bombay and The Club Mahabaleshwar DESCRIPTION: Neurodegeneration, a broad symptom which a
From playlist Axonal Transport and Neurodgenerative Disorders

Stanford Seminar: Amr Awadallah, Cloudera
EE203: The Entrepreneurial Engineer Speaker: Amr Awadallah, Cloudera Connect and engage with Stanford engineering and MBA graduate business owners as well as electrical energy, law and business contributors. A must for any prospective entrepreneurs with an engineering background, this s
From playlist Stanford EE203-The Entrepreneurial Engineer - Stanford Seminar Series

Wolfram Student Podcast Episode 7: Appropriate Punctuation for a String of Text
In the 7th episode of the Wolfram Student Podcast, we talk with Hozaifa Bhutta about his project in choosing the correct punctuation to be added to a string of text. Join us as we discuss the complex natural language processing he used and the neural network he created! #coding #wolfram #
From playlist Wolfram Student Podcast

The Physics of AI (Sponsored by IBM Watson) - Dario Gil (IBM)
Subscribe to O'Reilly on YouTube: http://goo.gl/n3QSYi Follow O'Reilly on: Twitter: http://twitter.com/oreillymedia Facebook: http://facebook.com/OReilly Instagram: https://www.instagram.com/oreillymedia LinkedIn: https://www.linkedin.com/company-beta/8459/
From playlist Artificial Intelligence Conference 2018 - New York, New York

Neural Network Architectures & Deep Learning
This video describes the variety of neural network architectures available to solve various problems in science ad engineering. Examples include convolutional neural networks (CNNs), recurrent neural networks (RNNs), and autoencoders. Book website: http://databookuw.com/ Steve Brunton
From playlist Data Science

1D convolution for neural networks, part 1: Sliding dot product
Part of an 9-part series on 1D convolution for neural networks. Catch the rest at https://e2eml.school/321
From playlist E2EML 321. Convolution in One Dimension for Neural Networks

DDPS | Turbulent disperse two-phase flows: simulations and data-driven modeling
In this DDPS talk from Aug. 26, 2021, University of Michigan Assistant Professor in Mechanical Engineering and Aerospace Engineering Jesse Capecelatro discusses a data-driven framework for model closure of the multiphase Reynolds Average Navier—Stokes (RANS) equations. Description: Turbu
From playlist Data-driven Physical Simulations (DDPS) Seminar Series