
Quentin Berthet: Learning with differentiable perturbed optimizers
Machine learning pipelines often rely on optimization procedures to make discrete decisions (e.g. sorting, picking closest neighbors, finding shortest paths or optimal matchings). Although these discrete decisions are easily computed in a forward manner, they cannot be used to modify model
From playlist Control Theory and Optimization

Plamen Turkedjiev: Least squares regression Monte Carlo for approximating BSDES and semilinear PDES
Abstract: In this lecture, we shall discuss the key steps involved in the use of least squares regression for approximating the solution to BSDEs. This includes how to obtain explicit error estimates, and how these error estimates can be used to tune the parameters of the numerical scheme
From playlist Probability and Statistics

(ML 11.4) Choosing a decision rule - Bayesian and frequentist
Choosing a decision rule, from Bayesian and frequentist perspectives. To make the problem well-defined from the frequentist perspective, some additional guiding principle is introduced such as unbiasedness, minimax, or invariance.
From playlist Machine Learning

We propose a sparse regression method capable of discovering the governing partial differential equation(s) of a given system by time series measurements in the spatial domain. The regression framework relies on sparsity promoting techniques to select the nonlinear and partial derivative
From playlist Research Abstracts from Brunton Lab

From playlist COMP0168 (2020/21)

(ML 19.2) Existence of Gaussian processes
Statement of the theorem on existence of Gaussian processes, and an explanation of what it is saying.
From playlist Machine Learning

Tamer Başar: "A General Theory for Discrete-Time Mean-Field Games"
High Dimensional Hamilton-Jacobi PDEs 2020 Workshop III: Mean Field Games and Applications "A General Theory for Discrete-Time Mean-Field Games" Tamer Başar - University of Illinois at Urbana-Champaign Abstract: In this lecture, I will present a general theory for mean-field games formul
From playlist High Dimensional Hamilton-Jacobi PDEs 2020

Adjoint Equation of a Linear System of Equations - by implicit derivative
Automatic Differentiation allows for easily propagating derivatives through explicit relations. The adjoint method also enables efficient derivatives over implicit relations like linear systems, which enables the computation of sensitivities. Here are the notes: https://raw.githubuserconte
From playlist Summer of Math Exposition Youtube Videos

Olfactory Search and Navigation (Lecture 2) by Antonio Celani
PROGRAM ICTP-ICTS WINTER SCHOOL ON QUANTITATIVE SYSTEMS BIOLOGY (ONLINE) ORGANIZERS Vijaykumar Krishnamurthy (ICTS-TIFR, India), Venkatesh N. Murthy (Harvard University, USA), Sharad Ramanathan (Harvard University, USA), Sanjay Sane (NCBS-TIFR, India) and Vatsala Thirumalai (NCBS-TIFR, I
From playlist ICTP-ICTS Winter School on Quantitative Systems Biology (ONLINE)

"RM Models for Online Advertising and On-Demand Platforms" by Philipp Afèche - Session IV
This mini-course focuses on revenue management applications in online advertising and on-demand platforms with time-sensitive customers that give rise to novel matching and queueing models. For example, online advertising platforms match impressions supply to advertiser demand, whereas on-
From playlist Thematic Program on Stochastic Modeling: A Focus on Pricing & Revenue Management
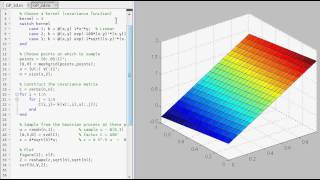
(ML 19.3) Examples of Gaussian processes (part 1)
Illustrative examples of several Gaussian processes, and visualization of samples drawn from these Gaussian processes. (Random planes, Brownian motion, squared exponential GP, Ornstein-Uhlenbeck, a periodic GP, and a symmetric GP).
From playlist Machine Learning

The Power of Sampling by Peter W. Glynn
Infosys-ICTS Turing Lectures The Power of Sampling Speaker: Peter W. Glynn (Stanford University, USA) Date: 14 August 2019, 16:00 to 17:00 Venue: Ramanujan Lecture Hall, ICTS Bangalore Sampling-based methods arise in many statistical, computational, and engineering settings. In engine
From playlist Infosys-ICTS Turing Lectures

(ML 19.5) Positive semidefinite kernels (Covariance functions)
Definition of a positive semidefinite kernel, or covariance function. A simple example. Explanation of terminology: autocovariance, positive definite kernel, stationary kernel, isotropic kernel, covariogram, positive definite function.
From playlist Machine Learning

Reinforcement Learning 1: Introduction to Reinforcement Learning
Hado Van Hasselt, Research Scientist, shares an introduction reinforcement learning as part of the Advanced Deep Learning & Reinforcement Learning Lectures.
From playlist DeepMind x UCL | Reinforcement Learning Course 2018

Data Science - Part XIII - Hidden Markov Models
For downloadable versions of these lectures, please go to the following link: http://www.slideshare.net/DerekKane/presentations https://github.com/DerekKane/YouTube-Tutorials This lecture provides an overview on Markov processes and Hidden Markov Models. We will start off by going throug
From playlist Data Science

Stanford CS234: Reinforcement Learning | Winter 2019 | Lecture 1 - Introduction - Emma Brunskill
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/ai Professor Emma Brunskill, Stanford University https://stanford.io/3eJW8yT Professor Emma Brunskill Assistant Professor, Computer Science Stanford AI for Human
From playlist Stanford CS234: Reinforcement Learning | Winter 2019

From playlist Contributed talks One World Symposium 2020

Reinforcement Learning 3: Markov Decision Processes and Dynamic Programming
Hado van Hasselt, Research scientist, discusses the Markov decision processes and dynamic programming as part of the Advanced Deep Learning & Reinforcement Learning Lectures.
From playlist DeepMind x UCL | Reinforcement Learning Course 2018

(ML 7.10) Posterior distribution for univariate Gaussian (part 2)
Computing the posterior distribution for the mean of the univariate Gaussian, with a Gaussian prior (assuming known prior mean, and known variances). The posterior is Gaussian, showing that the Gaussian is a conjugate prior for the mean of a Gaussian.
From playlist Machine Learning

Introduction to Multi-Agent Reinforcement Learning
Learn what multi-agent reinforcement learning is and some of the challenges it faces and overcomes. You will also learn what an agent is and how multi-agent systems can be both cooperative and adversarial. Be walked through a grid world example to highlight some of the benefits of both de
From playlist Reinforcement Learning