
History of test validity research
History of test validity research Task-based vs competency-based assessment: https://www.youtube.com/watch?v=LCEfIyxoClQ&list=PLTjlULGD9bNJi1NtMfKjr7umeKdQR9DGO&index=18 Test usefulness: https://www.youtube.com/watch?v=jZFeOaYkVzA&list=PLTjlULGD9bNJi1NtMfKjr7umeKdQR9DGO&index=7
From playlist Learn with Experts

What is a hypothesis test? The meaning of the null and alternate hypothesis, with examples. Overview of test statistics and confidence levels.
From playlist Hypothesis Tests and Critical Values

Reliability 1: External reliability and rater reliability and agreement
In this video, I discuss external reliability, inter- and intra-rater reliability, and rater agreement.
From playlist Reliability analysis

Can You Validate These Emails?
Email Validation is a procedure that verifies if an email address is deliverable and valid. Can you validate these emails?
From playlist Fun


Voting Theory: Fairness Criterion
This video define 4 Fairness Criterion for determining the winner of an election. Site: http://mathispower4u.com
From playlist Voting Theory

Prob & Stats - Bayes Theorem (2 of 24) What is the Sensitivity of a Test?
Visit http://ilectureonline.com for more math and science lectures! In this video I will explain what is and give examples of the sensitivity of a test. The sensitivity of a test indicates the probability that the subject will have a POSITIVE result when the subject is actually POSITIVE.
From playlist PROB & STATS 4 BAYES THEOREM

LambdaConf 2015 - Type Theory and its Meaning Explanations Jon Sterling
At the heart of intuitionistic type theory lies an intuitive semantics called the “meaning explanations." Crucially, when meaning explanations are taken as definitive for type theory, the core notion is no longer “proof” but “verification”. We’ll explore how type theories of this sort aris
From playlist LambdaConf 2015

Statistical Rethinking Fall 2017 - week04 lecture08
Week 04, lecture 08 for Statistical Rethinking: A Bayesian Course with Examples in R and Stan, taught at MPI-EVA in Fall 2017. This lecture covers Chapter 6. Slides are available here: https://speakerdeck.com/rmcelreath Additional information on textbook and R package here: http://xcel
From playlist Statistical Rethinking Fall 2017
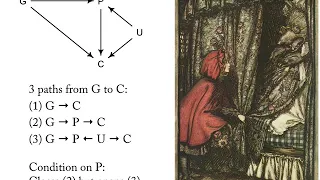
Statistical Rethinking Winter 2019 Lecture 07
Lecture 07 of the Dec 2018 through March 2019 edition of Statistical Rethinking: A Bayesian Course with R and Stan. This lecture covers the back-door criterion and introduction to Chapter 7, overfitting, cross-validation, and information criteria.
From playlist Statistical Rethinking Winter 2019
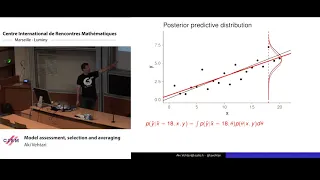
Aki Vehtari: Model assessment, selection and averaging
Abstract: The tutorial covers cross-validation, and projection predictive approaches for model assessment, selection and inference after model selection and Bayesian stacking for model averaging. The talk is accompanied with R notebooks using rstanarm, bayesplot, loo, and projpred packages
From playlist Probability and Statistics

Data BAD | What Will it Take to Fix Benchmarking for NLU?
The Coffee Bean explains and comments the sobering take of the paper "What Will it Take to Fix Benchmarking in Natural Language Understanding?" See more videos from Ms. Coffee Bean about natural language understanding: 📺 The road to NLU: https://youtube.com/playlist?list=PLpZBeKTZRGPMjF-O
From playlist Towards Natural Language Understanding (NLU)

Apply the EVT to the square function
👉 Learn how to find the extreme values of a function using the extreme value theorem. The extreme values of a function are the points/intervals where the graph is decreasing, increasing, or has an inflection point. A theorem which guarantees the existence of the maximum and minimum points
From playlist Extreme Value Theorem of Functions

Statistical Learning: 6.4 Estimating test error
Statistical Learning, featuring Deep Learning, Survival Analysis and Multiple Testing You are able to take Statistical Learning as an online course on EdX, and you are able to choose a verified path and get a certificate for its completion: https://www.edx.org/course/statistical-learning
From playlist Statistical Learning


Mixture Models 5: how many Gaussians?
Full lecture: http://bit.ly/EM-alg How many components should we use in our mixture model? We can cross-validate to optimise the likelihood (or some other objective function). We can also use Occam's razor, formalised as the Bayes Information Criterion (BIC) or Akaike Information Criterio
From playlist Mixture Models

Scenario 1: Federal Environmental Policy-Making
MIT 11.601 Introduction to Environmental Policy and Planning, Fall 2016 View the complete course: https://ocw.mit.edu/11-601F16 Instructor: Anna Nowogrodzki Federal environmental policy-making in the context of the scientific and political considerations behind fisheries management. Lice
From playlist MIT 11.601 Introduction to Environmental Policy and Planning

F-measure is a harmonic mean of recall and precision. Think of it as accuracy, but without the effect of true negatives (which made accuracy meaningless for evaluating search algorithms). F-measure can also be interpreted as the Dice coefficient between the relevant set and the retrieved s
From playlist IR13 Evaluating Search Engines

(ML 12.8) Other approaches to model selection
Brief mention of a few other approaches to model selection: AIC (Akaike Information Criterion), BIC (Bayesian Information Criterion), MDL (Minimum Description Length), and VC dimension.
From playlist Machine Learning