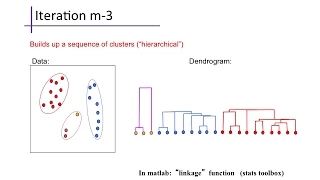
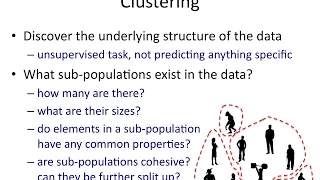
Clustering high-dimensional data
Clustering high-dimensional data is the cluster analysis of data with anywhere from a few dozen to many thousands of dimensions. Such high-dimensional spaces of data are often encountered in areas such as medicine, where DNA microarray technology can produce many measurements at once, and the clustering of text documents, where, if a word-frequency vector is used, the number of dimensions equals the size of the vocabulary. (Wikipedia).