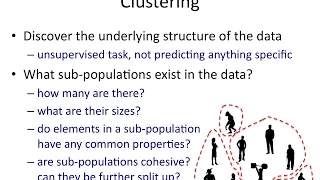
From playlist Clustering Algorithms

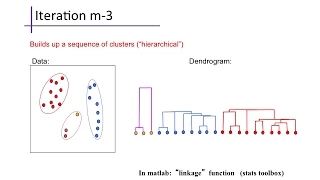
Clustering (2): Hierarchical Agglomerative Clustering
Hierarchical agglomerative clustering, or linkage clustering. Procedure, complexity analysis, and cluster dissimilarity measures including single linkage, complete linkage, and others.
From playlist cs273a

Introduction to Hierarchical Clustering with College Scorecard Data
Clustering is an unsupervised machine learning technique where data need not be labeled. The goal of clustering is to find like-items such as similar customers, similar products, or similar students, just to name a few. Popular clustering algorithms include K-means and hierarchical cluster
From playlist Fundamentals of Machine Learning

From playlist Hierarchical Clustering

Clustering Introduction - Practical Machine Learning Tutorial with Python p.34
In this tutorial, we shift gears and introduce the concept of clustering. Clustering is form of unsupervised machine learning, where the machine automatically determines the grouping for data. There are two major forms of clustering: Flat and Hierarchical. Flat clustering allows the scient
From playlist Machine Learning with Python

Hierarchical Clustering 5: summary
[http://bit.ly/s-link] Summary of the lecture.
From playlist Hierarchical Clustering

We will look at the fundamental concept of clustering, different types of clustering methods and the weaknesses. Clustering is an unsupervised learning technique that consists of grouping data points and creating partitions based on similarity. The ultimate goal is to find groups of simila
From playlist Data Science in Minutes

Clustering Coefficient - Intro to Algorithms
This video is part of an online course, Intro to Algorithms. Check out the course here: https://www.udacity.com/course/cs215.
From playlist Introduction to Algorithms

Clara Grazian: Finding structures in observations: consistent(?) clustering analysis
Abstract: Clustering is an important task in almost every area of knowledge: medicine and epidemiology, genomics, environmental science, economics, visual sciences, among others. Methodologies to perform inference on the number of clusters have often been proved to be inconsistent and in
From playlist SMRI Seminars

Clustering (4): Gaussian Mixture Models and EM
Gaussian mixture models for clustering, including the Expectation Maximization (EM) algorithm for learning their parameters.
From playlist cs273a

Serhiy Yanchuk - Adaptive dynamical networks: from multiclusters to recurrent synchronization
Recorded 02 September 2022. Serhiy Yanchuk of Humboldt-Universität presents "Adaptive dynamical networks: from multiclusters to recurrent synchronization" at IPAM's Reconstructing Network Dynamics from Data: Applications to Neuroscience and Beyond. Abstract: Adaptive dynamical networks is
From playlist 2022 Reconstructing Network Dynamics from Data: Applications to Neuroscience and Beyond

Marie Albenque: Geometry of the sign clusters in the infinite Ising-weighted triangulation
HYBRID EVENT Recorded during the meeting "Random Geometry" the January 17, 2022 by the Centre International de Rencontres Mathématiques (Marseille, France) Filmmaker: Guillaume Hennenfent Find this video and other talks given by worldwide mathematicians on CIRM's Audiovisual Mathematics
From playlist Probability and Statistics

Multigrain: a unified image embedding for classes (...) - Thirion - Workshop 3 - CEB T1 2019
Bertrand Thirion (INRIA) / 03.04.2019 Multigrain: a unified image embedding for classes and instances. Medical imaging involves high-dimensional data, yet their acquisition is obtained for limited samples. Multivariate predictive models have become popular in the last decades to fit som
From playlist 2019 - T1 - The Mathematics of Imaging

Machine Learning 3 - Generalization, K-means | Stanford CS221: AI (Autumn 2019)
For more information about Stanford’s Artificial Intelligence professional and graduate programs, visit: https://stanford.io/30Z6b0p Topics: Generalization, Unsupervised learning, K-means Percy Liang, Associate Professor & Dorsa Sadigh, Assistant Professor - Stanford University http://onl
From playlist Stanford CS221: Artificial Intelligence: Principles and Techniques | Autumn 2019

Learning - Lecture 4 - CS50's Introduction to Artificial Intelligence with Python 2020
00:00:00 - Introduction 00:00:15 - Machine Learning 00:01:15 - Supervised Learning 00:08:11 - Nearest-Neighbor Classification 00:12:30 - Perceptron Learning 00:33:19 - Support Vector Machines 00:39:31 - Regression 00:42:37 - Loss Functions 00:49:33 - Overfitting 00:55:44 - Regularization 0
From playlist CS50's Introduction to Artificial Intelligence with Python 2020

Learning from Multiple Biased Sources - Clayton Scott
Seminar on Theoretical Machine Learning Topic: Learning from Multiple Biased Sources Speaker: Clayton Scott Affiliation: University of Michigan Date: February 25, 2020 For more video please visit http://video.ias.edu
From playlist Mathematics

2020.05.14 Jack Hanson - Critical first-passage percolation (part 2)
Part 1: background and behaviour on regular trees Part 2: limit theorems for lattice first-passage times For many lattice models in probability, the high-dimensional behaviour is well-predicted by the behaviour of a corresponding random model defined on a regular tree. Rigorous results
From playlist One World Probability Seminar

